
» About » Archive » Submit » Authors » Search » Random » Specials » Statistics » Forum » RSS Feed Updates Daily
No. 3311: PCA base representation
First | Previous | 2018-06-12 | Next | Latest

First | Previous | 2018-06-12 | Next | Latest
Permanent URL: https://mezzacotta.net/garfield/?comic=3311
Strip by: Alien@System
{Two columns of strips, beginning with the first Garfield strip in the first row, followed by 39 very blurry versions of the strip. The second column ends with the 2018-03-29 strip; beforehand are very blurry versions of it, too}
The author writes:
In a follow-up to my last submission, here we see the attempt to represent two Garfield strips using the principal components from each year.
A neat feature of eigenvectors that isn't of particular note for the functionality of the Principal Component Analysis (or, for short, PCA) is that they form a so-called basis for their vector space. What this means in layman's terms is that each picture we used in the PCA has a unique representation using those components. We can write each picture as the mean of all pictures, plus 10% of that component, plus 7,5% of that, minus 8,253% of that, and so on. And there is only that one way to arrive at that picture; if we take different percentages of those principal components, we will never get the same result. In that way, those numbers of how much of what component we take identify our picture uniquely. This is obviously something nice for facial recognition, as it means being able to tell faces apart easily. It's especially easy because, as I explained before, we can throw out a few of those components which don't have much influence on the overall picture, and also components that are just lighting effects and not actually part of the face as such.
Of course, we can now try to do the same for pictures which weren't in our library that we ran our PCA over. For faces, it's pretty much a given that at some point, you'll find a face that's not like one you used to train the program. What happens then? It's easy enough to measure how much of each principal component is present in each picture. If we go back to the bird example given in my previous submission, we can see how more easily: we know how our three principal components relate to the original measurements. "Size" is a weighted sum of all three measurements: wing span, beak length and weight. "Flight ability" is the weighted difference between weight and wing span. And "beakness" is the difference between beak length and the sum of weight and wing span (to give three examples. I don't guarantee that a PCA run on an actual experiment with birds would reproduce those components). When we've made our original three measurements, we can just add them and subtract them and get our measurements along our principal components.
For our birds, we can even do the reverse with no problem. We take three numbers for size, flight ability and beakness, and can calculate back the wingspan, beak length and weight of our bird. If we do it first in one, and then the other direction, we arrive back at our original numbers, to hopefully nobody's surprise. But this works for our birds because we have as many principal components as we have dimensions. For our pictures, be they of faces or Garfield comics, we have less dimensions, because we only have as many as we have pictures in our training library. Obviously, somewhere in between, information got lost. If we start with a picture not from the library, measure it along our principal components, then add those principal components with those measurements back together, we won't get exactly our picture back. We get an approximation, one that can be good or bad depending on how well that picture fits in among those of the library. If we give it a face, we would probably get a very good approximation, because after all we have lots of face components that we can put our picture back together from. If however we give it, say, a picture of a potato, we won't get back a potato. We will get a blurry thing resembling a face that's bright in about the same spots as the potato. This is because our principal components do not have any "potatoness" axes, because none of our faces was a potato.
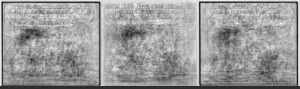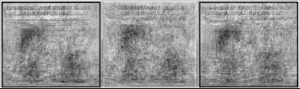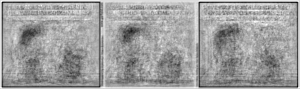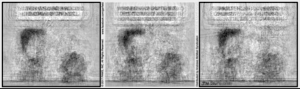
So what if we give our PCA of Garfield strips a Garfield strip? Well, if it's from the same year, obviously we get our picture back out perfectly, because it was used to get the principal components. But what of a different year? How well can we use the quintessence of Garfield, if one wants to be poetic, distilled from one year, to represent a new Garfield comic? That's what I tried out, and the picture above is the result.
I chose two strips of varying difficulty. One was the very first Garfield strip, from 1978-06-19, which is very unique. No other strip ever featured that particular setup of the characters again, with Jon in front of the worktable and Garfield on a dresser. The other was the last strip of Garfield as of the day I did this, 2018-03-29. By happy (for my purposes) coincidence, this strip is a very boring Jon left Garfield right strip. The only thing that moves is Jon's eyes. I guess it's not so happy for people who want to appreciate Garfield for its artistic value, but I had been planning to use such a strip, and didn't have to look further than today. Each row of two strips in my comic represents a year, beginning with 1979 at the top and ending with 2017 at the bottom, with our original strips in their respective years at the top and bottom for comparison.
Now how do we fare? As it turns out, badly. The old strip is never replicated in any recognisable form, no matter if we take the PCA from 1979 or 2017. That was to be expected, given that no strip had that layout again. The algorithm is basically fumbling around with puzzle pieces that don't fit the mold at all. One might, with some squinting and some creativity, claim that as the years go by that those blobs morph more and more into what seems a Jon left Garfield right standard format. Given that the principal components were trained with more variants of that standard format, it's of course plausible that our reassembled result looks more like that, but it's quite honestly not a very strong trend.
Quite different for the new strip. In 1979, we have a dark blob where Jon's hair goes, and a grey blob where Garfield is supposed to be. The rest of the picture is pretty noisy with dark lines from the components not quite adding up to a single-colour background. It's not surprising we get the hair right, given that Jon had that hairstyle since the beginning, and even is the best years, a few standard Jon left Garfield right strips snuck in, giving us a PCA to work with for getting the hair and a general Garfield shape. However, it's also not surprising we don't get it any better. Even if the same strip layout, with the same joke, had ran in 1979, the characters looked unlike their modern forms, and thus wouldn't have helped in getting the pixel values correct. As we go down the years, there is for the most part not much evolution, either. The hair stays around, and so does the blurry blob that is Garfield, picking up only a slight bit of definition along the way. Until we hit the current decade, and suddenly the strip clears up. The background becomes more uniformly bright, we can spot even the dark spot of Jon's collar, and Garfield's head is distinguishable from the shoulders. We can suddenly see that Jon has his eyes open in the middle panel, and the 2017 strip even gets rather close with the speech bubble layout.
If you don't want to scroll, here's the two columns as animated gifs, cycling through the years:

Why did we do so badly that even in those last years where all pictures look bland and are assembled with computers, we can't quite get a intelligible Garfield strip? That's because the PCA, even more so than for faces, can't actually recognise how Garfield strips work. It can only check which pixels are light or dark. If Jon is moved to the side by a few pixels, it will result in a rather different decomposition in principal components, although for humans nothing has actually noticeably changed. Just like for faces, our picture alone doesn't do the underlying structure justice. We'd need to analyse the Garfield strips differently first, take them apart in background, speech and characters, and then run a PCA over those, if we wanted to really do good. A good hint that what we'll get out of our PCA won't fully represent the structure is that our mean is not representative of our training library. The average of all Garfield strips is not a Garfield strip itself, it's a blur. The same is true for the simple implementation of Eigenfaces. If we first identify the faces by structure and texture, as discussed before, the average will look a lot more like a face, showing us once again that we need to give the PCA the right kind of data if we want to get useful stuff back out.
[[Original strips: all non-Sunday, non-leapday strips from 1979 to 2017, plus 1978-06-19 and 2018-03-29.]]
{kind=link}
{kind=link}
Original strips: 1978-06-19, 2018-03-29.
Irregular Webcomic! | Darths & Droids | Eavesdropper | Planet of Hats | The Prisoner of Monty Hall
mezzacotta | Lightning Made of Owls | Square Root of Minus Garfield | The Dinosaur Whiteboard | iToons | Comments on a Postcard | Awkward Fumbles
Garfield and associated character names and likenesses are registered trademarks of Paws, Inc., which does not sponsor, authorise, or endorse this site.
This is a fan-produced parody site. Original comic strips are copyright Paws, Inc. and are used here only as a vehicle for parody.
Original aspects of this work are licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported Licence by The Comic Irregulars. sromgsubmissions@gmail.com